Case study 3: Sibilant acoustics
Author: Massimo Lipari
Motivation
Various acoustic measures have been used over the years in the literature on sibilant fricatives (henceforth, just sibilants). Measures of the overall spectral peak and of the spectral center of gravity (the weighted mean frequency of the spectrum)–referred to as peak and COG below–both have long histories. More recently, it has become common to instead look for a ‘main’ peak (meant to correspond to the lowest resonance of the cavity anterior to the principal constriction) over a relatively narrow, pre-specified frequency range that can vary by sibilant and by speaker–this measure is sometimes referred to as FM [Koenig et al., 2013].
In this case study, we’ll compare the three measures for tokens of the voiceless sibilants /s/ and /ʃ/ in Quebec French.
- This case study demonstrates workflow for using an external tool to make measures:
Export token locations
Use external tool (here, an R script) to make measures per token
Import back into the database
Step 0: Preliminaries
For this case study, the data come from a corpus of parliamentary speech, the ParlBleu corpus [Lipari et al., 2024]. We’ll be using a subset of 6 speakers (3 female, 3 male), which can be downloaded here. The full corpus is also available on GitHub by request.
To begin, we’ll assume a file structure that looks like the following:
pgdb_case-studies (your working directory)
├── ParlBleu-subset (the corpus data)
│ ├── enrichment_data
│ │ ├── prototypes.csv (discussed later)
│ │ └── speaker_metadata.csv (a file containing speaker metadata)
│ ├── * (one folder for each speaker's data)
├── sibilants
│ ├── output
│ │ └── * (starts out empty, output files will be generated here)
│ ├── * (scripts go here)
Step 1: Importing
We first import the corpus into a PolyglotDB database, much like in Tutorial 1.
import polyglotdb.io as pgio
from polyglotdb import CorpusContext
def main():
# Set the path to the corpus (change this if you've put the corpus in a different location)
corpus_root = "../ParlBleu-subset/"
# Set the name of the PolyglotDB database that will be created for the corpus (can be anything)
corpus_name = "ParlBleu-subset"
# This tells PolyglotDB that the TextGrids are in the *Montreal Forced Aligner* format
parser = pgio.inspect_mfa(corpus_root)
parser.call_back = print
with CorpusContext(corpus_name) as c:
c.load(parser, corpus_root)
if __name__ == "__main__":
main()
Note
All the Python scripts in this case study us the so-called if __name__ == '__main__': idiom, where the code is wrapped in a function called main() that is executed only when the script is called directly. This is to avoid issues with the multiprocessing module.
Step 2: Enrichment
We now enrich the corpus with the information required for our case study.
We specify the set of phones which represent vowels in the corpus in the
vowel_setvariable. We then automatically syllabify all words, in this case assuming that vowels and only vowels are syllabic in this language.We then specify the set of word labels used to represent silences in the corpus with the
pause_labelsvariable. This allows us to split sound files into ‘utterances’–periods of speech surrounded by periods of silence of a predetermined minimum length (150 ms by default, but this can be changed by modifying themin_pause_lengthparameter to theencode_utterances()function).Finally, we want to add basic biographical information about the speakers (e.g., gender, year of birth), which we have stored in the
speaker_metadata.csvfile. The values in the first column of this file must match the PolyglotDB speaker ID (the name of the folder containing that speaker’s data); every other column is used to create new properties of speakers in the database (with the column name used as the property name).
from polyglotdb import CorpusContext
def main():
# Remember to change this if you changed it in step 1
corpus_name = "ParlBleu-subset"
# Specify the vowel set for this corpus
vowel_set = [
"a",
"e",
"i",
"o",
"u",
"y",
"ø",
"œ",
"œ̃",
"ɑ",
"ɑ̃",
"ɔ",
"ɔ̃",
"ə",
"ɛ",
"ɛ̃",
"ɜ",
]
print("Encoding vowel set...")
with CorpusContext(corpus_name) as c:
c.encode_type_subset("phone", vowel_set, "vowel")
print("Syllable enrichment...")
with CorpusContext(corpus_name) as c:
c.encode_type_subset("phone", vowel_set, "syllabic")
c.encode_syllables(syllabic_label="syllabic")
c.encode_count("word", "syllable", "num_syllables")
print("Utterance enrichment...")
# Specify the set of word labels which designate pauses
pause_labels = ["<SIL>"]
with CorpusContext(corpus_name) as c:
c.encode_pauses(pause_labels)
c.encode_utterances(min_pause_length=0.15)
print("Speaker enrichment...")
# Change this if you've moved the file on your computer
speaker_enrichment_file = "../ParlBleu-subset/enrichment_data/speaker_metadata.csv"
with CorpusContext(corpus_name) as c:
c.enrich_speakers_from_csv(speaker_enrichment_file)
if __name__ == "__main__":
main()
Step 3: Querying
In recent years, it has become standard to use multitaper spectra [Thomson, 1982] rather than garden-variety DFT spectra, for the reasons explained in Reidy [2013]. However, multitaper has not yet been implemented in PolyglotDB: we must therefore use external software–in this case, an R script, described in the next section. Accordingly, we need to run a simple query to extract all sibilant tokens we want to analyze (all prevocalic voiceless sibilants in onset position greater than 50 ms in duration), a total of 1434 tokens. For reasons which will become clear shortly, we’ll also need to query the list of utterances in the corpus.
from polyglotdb import CorpusContext
def main():
corpus_name = "ParlBleu-subset"
utterances_export_path = "./output/ParlBleu-subset_utterances.csv"
sibilants_export_path = "./output/ParlBleu-subset_sibilants.csv"
# Getting utterances
print("Querying all utterances...")
with CorpusContext(corpus_name) as c:
q = c.query_graph(c.utterance).columns(
c.utterance.speaker.name.column_name("speaker"),
c.utterance.id.column_name("utterance_label"),
c.utterance.begin.column_name("utterance_begin"),
c.utterance.end.column_name("utterance_end"),
c.utterance.following.begin.column_name("following_utterance_begin"),
c.utterance.following.end.column_name("following_utterance_end"),
c.utterance.discourse.name.column_name("discourse"),
c.utterance.discourse.speech_begin.column_name("discourse_begin"),
c.utterance.discourse.speech_end.column_name("discourse_end"),
)
q.order_by(c.phone.discourse.name)
q.to_csv(utterances_export_path)
# Getting sibilants
print("Querying all onset, pre-vocalic voiceless sibilant tokens >= 50 ms in duration...")
with CorpusContext(corpus_name) as c:
q = (
c.query_graph(c.phone)
.filter(
c.phone.label.in_(["s", "ʃ"]),
c.phone.following.subset == "vowel",
c.phone.begin == c.phone.syllable.begin,
c.phone.duration >= 0.05,
)
.columns(
c.phone.discourse.name.column_name("discourse"),
c.phone.utterance.speaker.name.column_name("speaker"),
c.phone.utterance.speaker.gender.column_name("gender"),
c.phone.label.column_name("phone"),
c.phone.duration.column_name("phone_duration"),
c.phone.begin.column_name("phone_begin"),
c.phone.end.column_name("phone_end"),
c.phone.word.phone.position.column_name("phone_position"),
c.phone.previous.label.column_name("previous_phone"),
c.phone.following.label.column_name("following_phone"),
c.phone.syllable.label.column_name("syllable"),
c.phone.syllable.begin.column_name("syllable_begin"),
c.phone.syllable.end.column_name("syllable_end"),
c.phone.word.label.column_name("word"),
c.phone.word.transcription.column_name("transcription"),
c.phone.syllable.word.begin.column_name("word_begin"),
c.phone.syllable.word.end.column_name("word_end"),
c.phone.syllable.word.utterance.begin.column_name("utterance_begin"),
c.phone.syllable.word.utterance.begin.column_name("utterance_end"),
)
)
q.order_by(c.phone.discourse.name)
q.to_csv(sibilants_export_path)
if __name__ == "__main__":
main()
Step 4: Multitaper spectra
To compute the multitaper spectra and obtain the desired acoustic measures, we’ll adapt the R script used in Sonderegger et al. [2023], which is available on that paper’s OSF repository in the measurement directory. This script implements a clever amplitude normalization scheme for the sibilant spectra (described in detail in the paper), which attempts to determine the average noise profile of each utterance and uses this to scale the spectra for each token bin-by-bin.
The modified script is labelled 4_generate-mts-measures.R: it’s too long to show here, but is available for download at the following link. The set of acoustic measures extracted was changed to better suit our purposes. (Additional changes were made to allow measures from multiple timepoints over the course of the sibilant to be extracted, rather than just measures at the midpoint, but this functionality won’t be used here.)
There are a few technical details about the implementation in the script that are worth noting now:
With this script, the multitaper spectra are always generated using 8 tapers (
k = 8) and a bandwidth parameter of 4 (nW = 4);Although the original sampling rate of the audio files is 44100 Hz, audio will be downsampled to 22050 Hz before the analysis;
As is common in the literature, peak and COG are not quite calculated over the entire frequency interval. A lower limit of 1000 Hz (to essentially eliminate the effects of voicing) and an upper limit of 11000 Hz (ever so slightly below the Nyquist frequency) are used;
The ranges used here for FM are those suggested as reasonable estimates in Shadle [2023]: for /s/, 3000-8000 Hz for women and 3000-7000 Hz for men; for /ʃ/, 2000-4000 Hz for both women and men.
Note
The above ranges for FM may not be suitable for all speakers: notably, some speakers (especially women) may produce /s/ with a main peak above 8000 Hz. Shadle [2023] cautions that it is generally best to determine speaker- and sibilant- specific ranges after having manually examined a certain number of sibilant spectra. Of course, this may not always be feasible for large corpora. For a more sophisticated FM detection algorithm than is used here, see the fricative() function of Keith Johnson and Ronald Sprouse’s phonlab package (documention here).
In order for the script to run, we must also download a few additional scripts developed by Patrick Reidy (and make a single change to one of them), as described here. These must be placed in an auxiliary folder, which itself must be in the same directory as 4_generate-mts-measures.R. You should end up with a folder structure which looks like the following:
pgdb_case-studies
├── ParlBleu-subset
│ ├── *
├── sibilants
│ ├── auxiliary
│ │ ├── DPSS.R
│ │ ├── Multitaper.R
│ │ ├── Periodrogram.R
│ │ ├── Spectrum.R
│ │ └── Waveform.R (with the relevant change made per the linked instructions)
│ ├── output
│ │ ├── ParlBleu-subset_sibilants.csv
│ │ └── ParlBleu-subset_utteraces.csv
│ ├── * (scripts for steps 1-3)
│ ├── 4_generate-mts-measures.R
Making sure we’re in the sibilants folder, we’ll now run 4_generate-mts-measures.R from the command line. We do this twice: the first pass will generate the utterance mean spectra used for normalization, and the second pass will generate the sibilant spectra.
First, we run the command: Rscript 4_generate-mts-measures.R ./output/ParlBleu-subset_utterances.csv ../ParlBleu-subset/ output/ -f 0.035 -d -w discourse -p mean_spectrum.
Here’s what each argument does:
The positional arguments specify (in order) the path to the CSV file containing the utterances to measure, the path to the root of the corpus, and the path to the directory where the output data (the RData file containing the utterance spectra) should be saved;
The
-fflag specifies the length of the analysis window to use in seconds–here,0.035(35 ms);The
-dflag tells the script that the corpora is organized such that each speaker has their own directory (rather than all sound files being in a single directory);The
-wflag specifies the column of the CSV which contains the sound file names;The
-pflag, with the value mean_spectrum, tells the program we want spectra for utterances (rather than for sibilants).
Once this finishes, we run the command: Rscript 4_generate-mts-measures.R ./output/ParlBleu-subset_sibilants.csv ../ParlBleu-subset/ output/ -f 0.035 -d -w discourse -p sibilant -z -m 0.5.
Here’s what each argument does:
The positional arguments do the same thing as above (note: the output directory must be the same as that used in the mean_spectrum step);
The
-f,-d,-wflags do the same as above;The
-pflag, with the valuesibilant, tells the program we want spectra for sibilants (rather than for utterances);The
-zflag specifies that we want to apply the amplitude normalization scheme;The
-mflag specifies the timepoint(s) at which measurements are desired–in our case, a value of0.5is used to obtain measurements at sibilant midpoint.
Note
4_generate-mts-measures.R uses multiprocessing to speed up run times. By default, 8 cores are used: this can be changed with the -j flag.
Step 5: Analysis
Finally, we use an R script to make a quick plot of each of the three measures by phone and by speaker.
library(tidyverse)
theme_set(theme_bw())
# Colourblind-friendly colours from Okabe & Ito (https://jfly.uni-koeln.de/color/#pallet)
oi_colours <- c('#E69F00', '#56B4E9', '#009E73')
# Load the data
sibilants <- read_csv('./output/ParlBleu-subset_mts_sibilants_normalized.csv')
# Make the figure
sibilant_measures <- sibilants %>%
pivot_longer(cols = c(spectral_peak_full:F_M),
names_to = 'acoustics',
values_to = 'value') %>%
mutate(acoustics = acoustics %>% fct_relevel(c('spectral_peak_full', 'spectral_cog', 'F_M'))) %>%
ggplot(aes(x = phone, y = value, colour = acoustics)) +
geom_boxplot(position = position_dodge(width = 0.85)) +
facet_wrap(~interaction(speaker, gender %>% str_to_title(), sep = ', '),
scales = 'free_x') +
labs(x = NULL,
y = 'Frequency (Hz)',
colour = 'Acoustic measure') +
scale_colour_discrete(labels = c('Peak', 'COG', 'F_M'), type = oi_colours) +
theme(legend.position = 'bottom')
sibilant_measures
sibilant_measures %>% ggsave('./sibilant_measures.png', ., width = 1600, height = 1200, unit = 'px')
The output looks like this:
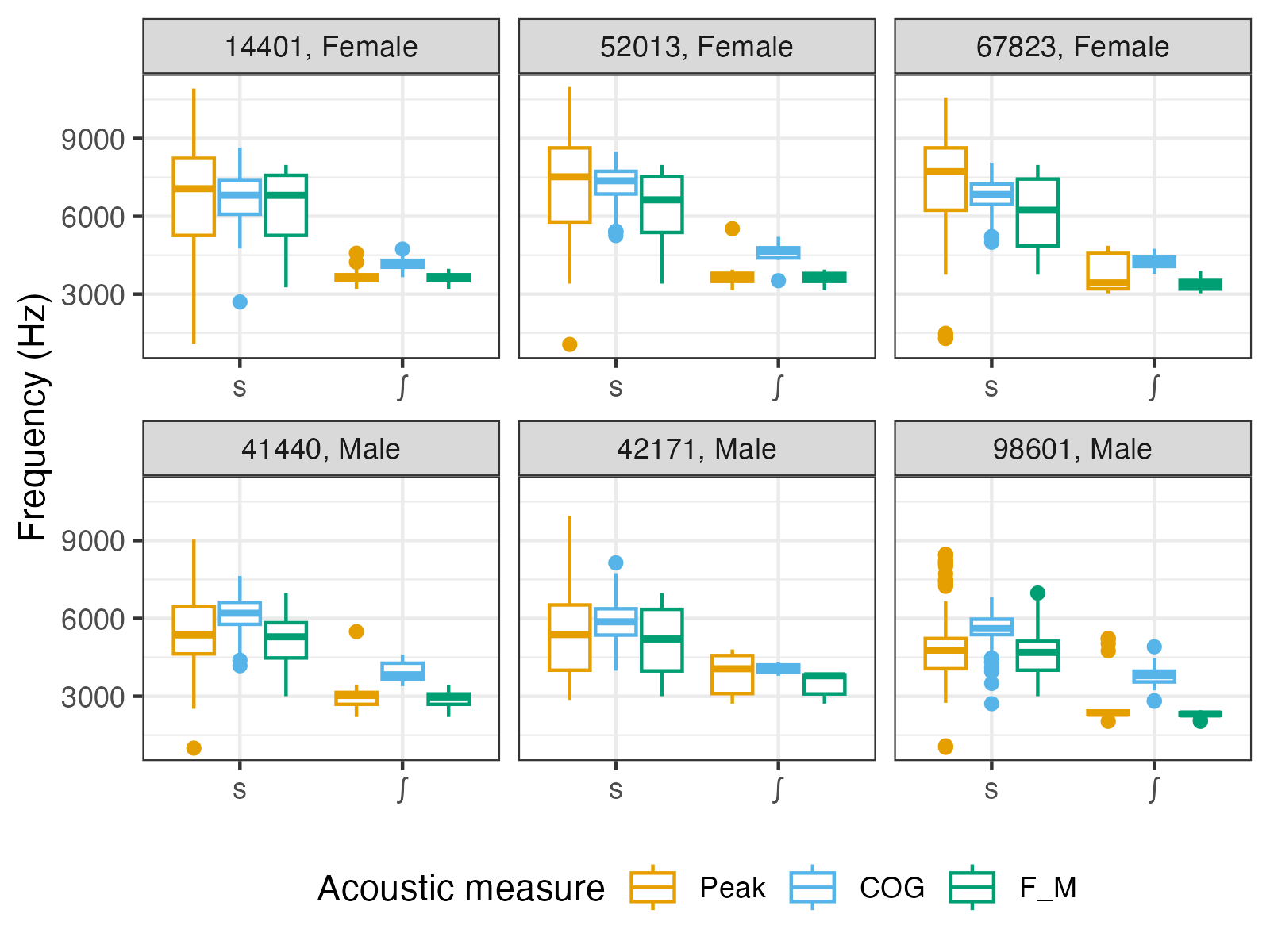
Overall, the three measures seem to tell a similar story (which is expected). There are, however, several things worth noting.
Amongst the measures, peak has the highest variance and produces a sizeable number of both high and low outliers (especially for /s/).
While the speaker means of peak and FM are roughly the same (since for a large number of tokens, peak == FM), that of COG tends to be slightly higher. This is especially evident for /ʃ/ and for the male speakers, and likely reflects the presence of an additional, higher-frequency (but lower-amplitude) peak in these spectra (assuming this peak would often be above 11 kHz in female /s/).
The distribution of FM for speaker 14401’s /s/ appears slightly left-skewed. This may be an indication that an upper limit of 8000 Hz may be somewhat too low for this speaker.