Neo4j implementation
This section details how PolyglotDB saves and structures data within Neo4j.
Note
This section assumes some familiarity with the Cypher query language and Neo4j, see the Cypher documentation for more details and reference.
Annotation Graphs
The basic formalism in PolyglotDB for modelling and storing transcripts is that of annotation graphs, originally proposed by Bird & Liberman (1999). In this formalism, transcripts are directed acyclic graphs. Nodes in the graph represent time points in the audio file and edges between the nodes represent annotations (such as phones, words, utterances, etc). This style of graph is illustrated below.
Note
Annotation is a broad term in this conceptual framework and basically represents anything that can be defined as a label, and begin/end time points. Single time point annotations (something like ToBI) are not strictly covered in this framework. Annotations as phoneticians typically think of annotation (i.e., extra information annotated by the researcher like VOT or categorization by listener) is modelled in PolyglotDB as Subannotations (annotations of annotations) and are handled differently than the principle annotations which are linguistic units.
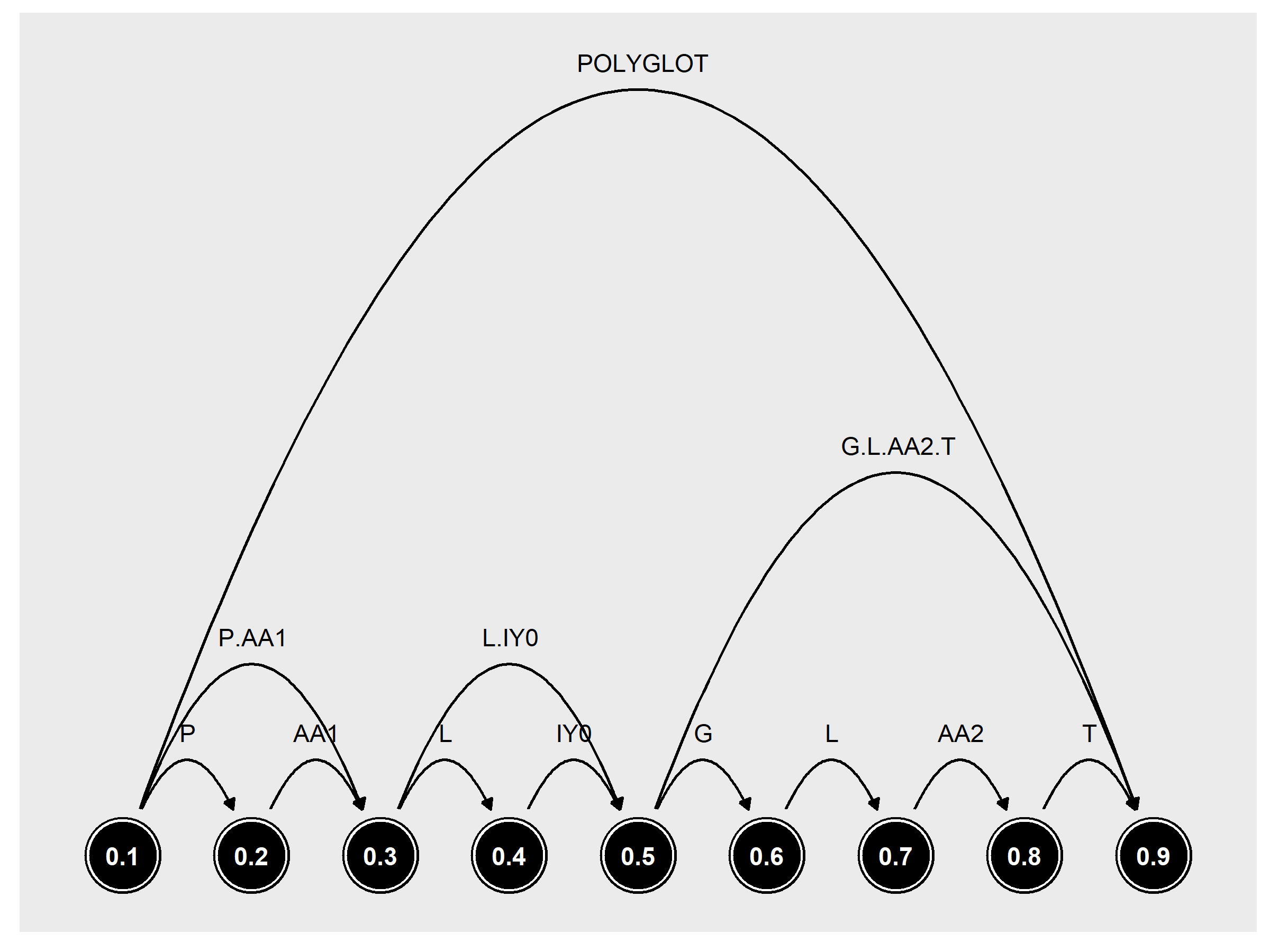
Fig. 1 Annotation graph representation of the word “polyglot” spoken over the course of one second.
The annotation graph framework is a conceptual way to model linear time signals and interval annotations, independent of a specific implementation. The annotation graph formalism has been implemented in other speech corpus management systems, in either SQL (LaBB-CAT) or custom file-based storage systems (EMU-SDMS). One of the principle goals in developing PolyglotDB was to be scalable to large datasets (potentially hundreds of hours) and still have good performance in querying the database. Initial implementations in SQL were not as fast as I would have liked, so Neo4j was selected as the storage backend. Neo4j is a NoSQL graph database where nodes and edges are fundamental elements in both the storage and Cypher query language. Given its active development and use in enterprise systems, it is the best choice for meeting the scalability and performance considerations.
However, Neo4j prioritizes nodes far more than edges (see Neo4j’s introductory materials for more details). In general, their use case is primarily something like IMDB, for instance. In such a case, you’ll have nodes for movies, shows, actors, directors, crew, etc, each with different labels associated with them. Edges represent relationships like “acted in”, or “directed”. The nodes have the majority of the properties, like names, dates of birth, gender, etc, and relationships are sparse/empty. The annotation graph formalism has nodes being relatively sparse (just time point), and the edges containing the properties (label, token properties, speaker information, etc). Neo4j uses indices to speed up queries, but these are focused on node properties rather than edge properties (or were at the beginning of development). As such, the storage model was modified from the annotation graph formalism into something more node-based, seen below.
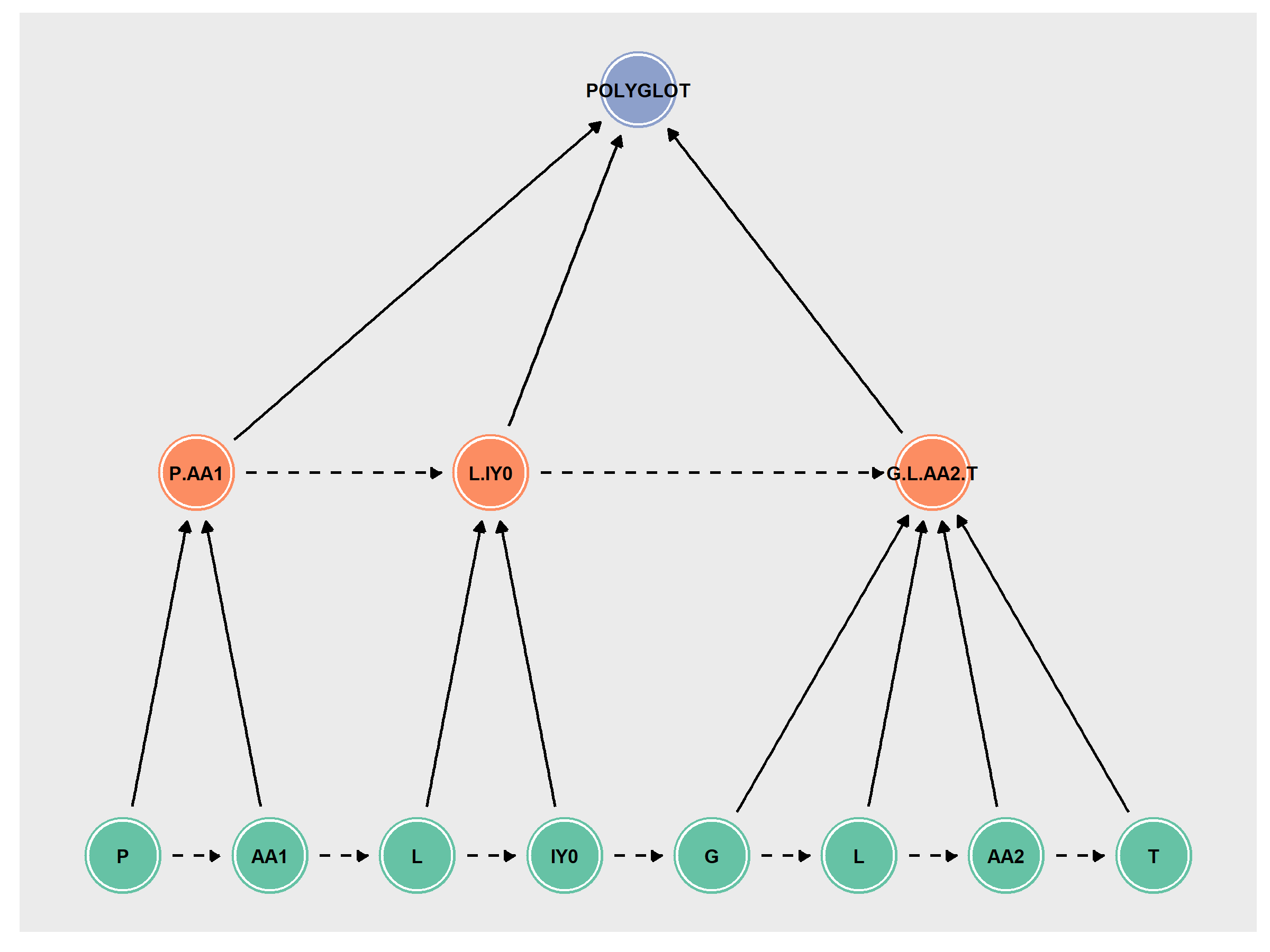
Fig. 2 PolyglotDB implementation of the annotation graph formalism for a production of the word “polyglot”.
Rather than time points as nodes, the actual annotations are nodes, and relationships between them are either hierarchical
(i.e., the phone P is contained by the syllable P.AA1, represented by solid lines in the figure above)
or precedence (the phone P precedes the phone AA1, represented by dashed lines in the figure above).
Each node has properties for begin and end time points, as well as any arbitrary encoded information
(i.e., part of speech tags). Each node of a given annotation type (word, syllable, phone) is labelled as such in Neo4j,
speeding up queries.
All interaction with corpus data is done through the CorpusContext class. When this class
is instantiated, and then used as a context manager, it connects to both a Neo4j database and an InfluxDB database (described
in more detail in InfluxDB implementation). When a corpus is imported (see Importing corpora), nodes and edges in
the Neo4j database are created, along with appropriate labels on the nodes to organize and aid querying. By default, from
a simple import of forced aligned TextGrids, the full list of node types in a fresh PolyglotDB Neo4j database is as follows:
:phone
:phone_type
:word
:word_type
:Speaker
:Discourse
:speech
In the previous figure (Fig. 2), for instance, all green nodes would have the Neo4j label :phone, all orange nodes would have the Neo4j label :syllable,
and the purple node would have the Neo4j label :word. All nodes would also have the Neo4j label :speech. Each of the nodes in figure
would additionally have links to other aspects of the graph. The word node would have a link to a node with the Neo4j label of :word_type,
the syllables nodes would each link a node with the Neo4j label :syllable_type, and the phone nodes would link to nodes with Neo4j label of :phone_type.
These type nodes would then contain any type information that is not dependent on the particular production. Each node in the figure would also
link to a :Speaker node for whoever produced the word, as well as a :Discourse node for whichever file it was recorded in.
Note
A special tag for the corpus name is added to every node in the corpus, in case multiple corpora are imported in the
same database. For instance, if the CorpusContext is instantiated as CorpusContext('buckeye'), then any imported
annotations would have a Neo4j label of :buckeye associated with them. If another CorpusContext was instantiated
as CorpusContext('not_buckeye'), then any queries for annotations in the buckeye corpus would not be found, as
it would be looking only at annotations tagged with the Neo4j label :not_buckeye.
The following node types can further be added to via enrichment (see Enrichment):
:pause
:utterance
:utterance_type (never really used)
:syllable
:syllable_type
In addition to node labels, Neo4j and Cypher use relationship labels on edges in queries. In the above example, all solid
lines would have the label of :contained_by, as the lower annotation is contained by the higher one (see Corpus hierarchy representation below
for details of the hierarchy implementation). All the dashed lines would have the Neo4j label of :precedes as the previous annotation
precedes the following one.
The following is a list of all the relationship types in the Neo4j database:
:is_a (relation between type and token nodes)
:precedes (precedence relation)
:precedes_pause (precedence relation for pauses when encoded)
:contained_by (hierarchical relation)
:spoken_by (relation between tokens and speakers)
:spoken_in (relation between tokens and discourses)
:speaks_in (relation between speakers and discourses)
:annotates (relation between annotations and subannotations)
Corpus hierarchy representation
Neo4j is a schemaless database, each node can have arbitrary information added to it without requiring that information on any other node. However, enforcing a bit of a schema on the Neo4j is helpful for dealing with corpora which are more structured than an arbitrary graph. For a user, knowing that a typo leads to a property name that doesn’t exist on any annotations that they’re querying is useful. Additionally, knowing the type of the data stored (string, boolean, float, etc) allows for restricting certain operations (for instance, calculating a by speaker z-score is only relevant for numeric properties). As such a schema in the form of a Hierarchy is explicitly defined and used in PolyglotDB.
Each CorpusContext has a polyglotdb.structure.Hierarchy object which stores metadata about the corpus.
Hierarchy objects are basically schemas for the Neo4j database, telling the user what information annotations of a given type
should have (i.e., do word annotations have frequency as a type property? part_of_speech as a token property?).
Additionally it also gives the strict hierarchy between levels of annotation. A freshly imported corpus with just words and phones
will have a simple hierarchy that phones are contained by words. Enrichment can add more levels to the hierarchy for syllables
and utterances. All aspects of the Hierarchy object are stored in the Neo4j database and synced with the CorpusContext object.
In the Neo4j graph, there is a Corpus root node, with all encoded annotations linked as they would be
in an annotation graph for a given discourse (i.e., Utterance -> Word -> Syllable -> Phone in orange below). These nodes contain
a list of properties that will be found on each node in the annotation graphs (i.e., label, begin, end),
along with what type of data each property is (i.e., string, numeric, boolean, etc). There will also be a property for subsets that
is a list of all the token subsets of that annotation type.
Each of these
annotations are linked to type nodes (in blue below) that has a list of properties that belong to the type (i.e., in the figure below, word types
have label, transcription and frequency).
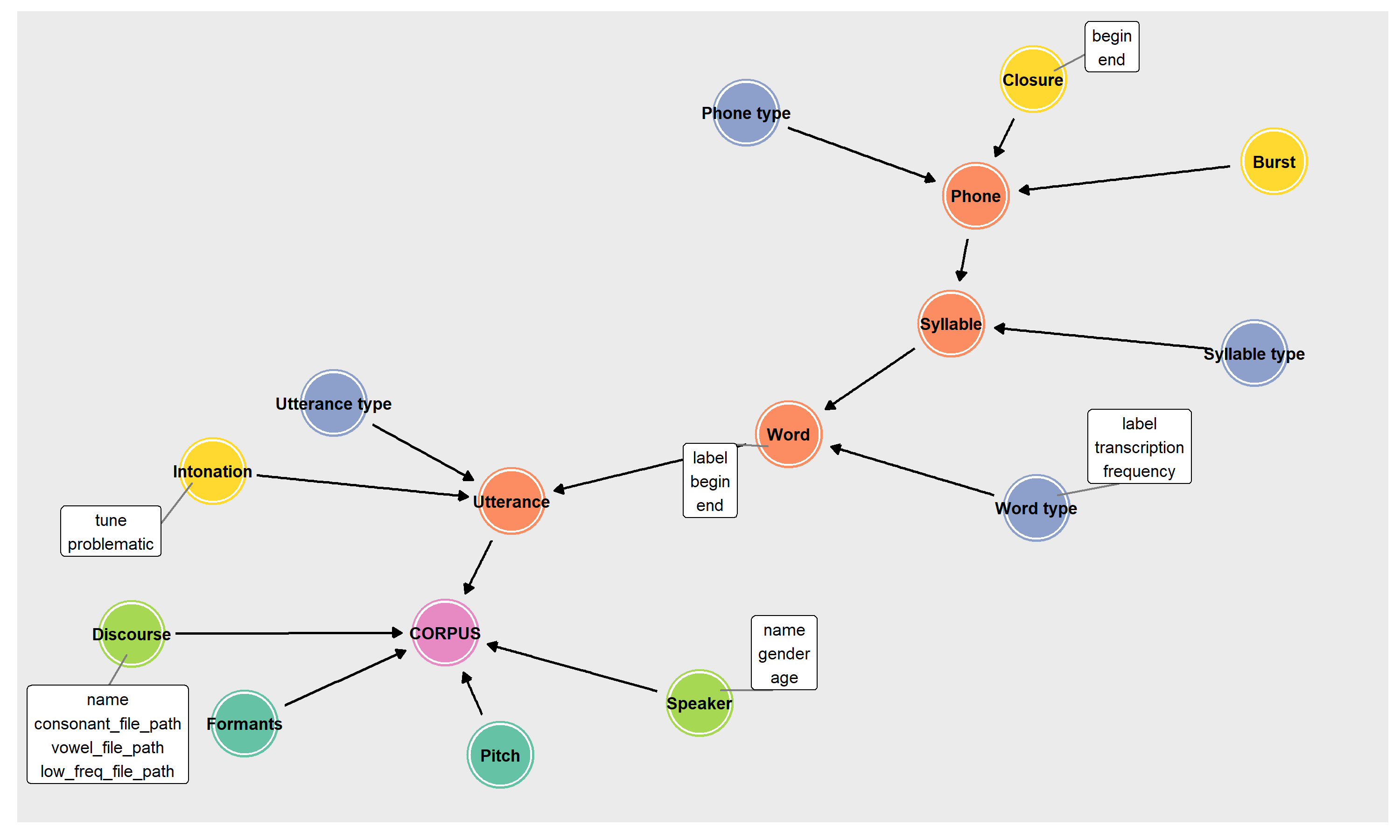
In addition, if subannotations are encoded, they will be represented in the hierarchy graph as well (i.e., Burst,
Closure, and Intonation in yellow above), along with all the properties they contain. Speaker
and Discourse properties are encoded in the graph hierarchy object as well as any acoustics that have been encoded
and are stored in the InfluxDB portion of the database (see Saving acoustics for details on encoding acoustic measures).
Query implementation
One of the primary functions of PolyglotDB is querying information in the Neo4j databases. The fundamental function of the polyglotdb.query module
is to convert Python syntax and objects (referred to as PolyglotDB queries below) into Cypher strings that extract the correct
elements from the Neo4j database. There is a fair bit of “magic” behind the scenes as much of this conversion is done by hijacking
built in Python functionality. For instance c.phone.label == 'AA1' does not actually return a boolean, but rather
a Clause object. This Clause object has functionality for generating a Cypher string like node_phone.label = 'AA1', which
would then be slotted into the appropriate place in the larger Cypher query. There is a larger Query object that has many subobjects,
such a filters, and columns to return, and uses these subobjects to slot into a query template to generate the final Cypher query.
This section attempts to break down the individual pieces that get added together to create the final Cypher query.
There are 4 principle types
of queries currently implemented in PolyglotDB based on the information desired (annotations, lexicon, speaker, and discourse
queries). Annotation queries are the most common, as they will search over the produced annotation tokens in discourses. For instance,
finding all stops in a particular environment and returning relevant information is going to be an annotation query with each
matching token having its own result.
Lexicon queries are queries over annotation types rather than tokens. Speaker and Discourse queries are those over their
respective entities.
Queries are constructed as Python objects (descended from polyglotdb.query.base.query.BaseQuery) and are generated
from methods on a CorpusContext object, as below. Each of the four types of queries has their
own submodule within the polyglotdb.query module.
Data type |
CorpusContext method |
Query class |
|---|---|---|
Annotations |
|
|
Lexicon |
|
|
Speaker |
|
|
Discourse |
|
The main structure of each of the query submodules is as follows:
The following walk through of the basic components of a query submodule will use a speaker query for illustration purposes.
In this example, we’ll be trying to extract the list of male speakers (with the assumption that speakers have been encoded
for gender and that the corpus is appropriately named corpus). In Cypher, this query would be:
MATCH (node_Speaker:Speaker:corpus)
WHERE node_Speaker.gender = "male"
RETURN node_Speaker.name AS speaker_name
This query in polyglotdb would be:
with CorpusContext('corpus') as c:
q = c.query_speakers() # Generate SpeakerQuery object
q = q.filter(c.speaker.gender == 'male') # Filter to just the speakers that have `gender` set to "male"
q = q.columns(c.speaker.name.column_name('speaker_name')) # Return just the speaker name (with the `speaker_name` alias)
results = q.all()
The attributes.py file contains the definitions of classes corresponding to nodes and attributes in the Neo4j database.
These classes have code for how to represent them in cypher queries and how properties are extracted. As an example of a somewhat simple case,
consider polyglotdb.query.speaker.attributes.SpeakerNode and polyglotdb.query.speaker.attributes.SpeakerAttribute.
A SpeakerNode object will have an alias in the Cypher query of node_Speaker and an initial look up definition for
the query as follows:
(node_Speaker:Speaker:corpus)
The polyglotdb.query.speaker.attributes.SpeakerAttribute class is used for the gender and name
attributes referenced in the query. These are created through calling c.speaker.gender (the __getattr__ method for
both the CorpusContext class and the SpeakerNode class are overwritten to allow for this kind of access).
Speaker attributes use their node’s alias to construct how they are referenced in Cypher, i.e. for c.speaker.gender:
node_Speaker.gender
When the column_name function is called, an output alias is used when constructing RETURN statements in Cypher:
node_Speaker.name AS speaker_name
The crucial part of a query is, of course, the ability to filter. Filters are constructed using Python operators, such as
== or !=, or functions replicating other operators like .in_(). Operators on attributes return
classes from the elements.py file of a query submodule. For instance, the polyglotdb.query.base.elements.EqualClauseElement
is returned when the == is used (as in the above query), and this object handles how to convert the operator into
Cypher, in the above case of c.speaker.gender == 'male', it will generate the following Cypher code when requested:
node_Speaker.gender = "male"
The query.py file contains the definition of the Query class descended from polyglotdb.query.base.query.BaseQuery.
The filter and columns methods allow ClauseElements and Attributes to be added for the construction of the
Cypher query. When all is called (or cypher which does the actual creation of the Cypher string), the first step
is to inspect the elements and attributes to see what nodes are necessary for the query. The definitions of each of these nodes are then
concatenated into a list for the MATCH part of the Cypher query, giving the following for our example:
MATCH (node_Speaker:Speaker:corpus)
Next the filtering elements are constructed into a WHERE clause (separated by AND for more than one element),
giving the following for our example:
WHERE node_Speaker.gender = "male"
And finally the RETURN statement is constructed from the list of columns specified (along with their specified column names):
RETURN node_Speaker.name AS speaker_name
If columns are not specified in the query, then a Python object containing all the information of the node is returned, according
to classes in the models.py file of the submodule. For our speaker query, if the columns are omitted, then the returned
results will have all speaker properties encoded in the corpus. In terms of implementation, the following query in polyglotdb
with CorpusContext('corpus') as c:
q = c.query_speakers() # Generate SpeakerQuery object
q = q.filter(c.speaker.gender == 'male') # Filter to just the speakers that have `gender` set to "male"
results = q.all()
print(results[0].name) # Get the name of the first result
will generate the following Cypher query:
MATCH (node_Speaker:Speaker:corpus)
WHERE node_Speaker.gender = "male"
RETURN node_Speaker
Annotation queries
Annotation queries are the most complicated kind due to all of the relationships linking nodes. Where Speaker, Discourse and Lexicon queries are really just lists of nodes with little linkages between nodes, Annotation queries leverage the relationships in the annotation graph quite a bit.
Basic query
Given a relatively basic query like the following:
with CorpusContext('corpus') as c:
q = c.query_graph(c.word)
q = q.filter(c.word.label == 'some_word')
q = q.columns(c.word.label.column_name('word'), c.word.transcription.column_name('transcription'),
c.word.begin.column_name('begin'),
c.word.end.column_name('end'), c.word.duration.column_name('duration'))
results = q.all()
Would give a Cypher query as follows:
MATCH (node_word:word:corpus)-[:is_a]->(node_word_type:word_type:corpus),
WHERE node_word_type.label = "some_word"
RETURN node_word_type.label AS word, node_word_type.transcription AS transcription,
node_word.begin AS begin, node_word.end AS end,
node_word.end - node_word.begin AS duration
The process of converting the Python code into the Cypher query is similar to the above Speaker example, but each step has
some complications. To begin with, rather than defining a single node, the annotation node definition contains two nodes, a word token
node and a word type node linked by the is_a relationship.
The use of type properties allows for a more efficient look up on the label property (for convenience and debugging, word
tokens also have a label property). The Attribute objects will look up what properties are type vs token for constructing
the Cypher statement.
Additionally, duration is a special property that is calculated based off of the token’s begin and end
properties at query time. This way if the time points are updated, the duration remains accurate. In terms of efficiency,
subtraction at query time is not costly, and it does save on space for storing an additional property. Duration can still be
used in filtering, i.e.:
with CorpusContext('corpus') as c:
q = c.query_graph(c.word)
q = q.filter(c.word.duration > 0.5)
q = q.columns(c.word.label.column_name('word'),
c.word.begin.column_name('begin'),
c.word.end.column_name('end'))
results = q.all()
which would give the Cypher query:
MATCH (node_word:word:corpus)-[:is_a]->(node_word_type:word_type:corpus),
WHERE node_word.end - node_word.begin > 0.5
RETURN node_word_type.label AS word, node_word.begin AS begin,
node_word.end AS end, AS duration
Precedence queries
Aspects of the previous annotation can be queried via precedence queries like the following:
with CorpusContext('corpus') as c:
q = c.query_graph(c.phone)
q = q.filter(c.phone.label == 'AE')
q = q.filter(c.phone.previous.label == 'K')
results = q.all()
will result the following Cypher query:
MATCH (node_phone:phone:corpus)-[:is_a]->(node_phone_type:phone_type:corpus),
(node_phone)<-[:precedes]-(prev_1_node_phone:phone:corpus)-[:is_a]->(prev_1_node_phone_type:phone_type:corpus)
WHERE node_phone_type.label = "AE"
AND prev_1_node_phone_type.label = "K"
RETURN node_phone, node_phone_type, prev_1_node_phone, prev_1_node_phone_type
Hierarchical queries
Hierarchical queries are those that reference some annotation higher or lower than the originally specified annotation. For instance to do a search on phones and also include information about the word as follows:
with CorpusContext('corpus') as c:
q = c.query_graph(c.phone)
q = q.filter(c.phone.label == 'AE')
q = q.filter(c.phone.word.label == 'cat')
results = q.all()
This will result in Cypher query as follows:
MATCH (node_phone:phone:corpus)-[:is_a]->(node_phone_type:phone_type:corpus),
(node_phone_word:word:corpus)-[:is_a]->(node_phone_word_type:word_type:corpus),
(node_phone)-[:contained_by]->(node_phone_word)
WHERE node_phone_type.label = "AE"
AND node_phone_word_type.label = "cat"
RETURN node_phone, node_phone_type, node_phone_word, node_phone_word_type
Spoken queries
Queries can include aspects of speaker and discourse as well. A query like the following:
with CorpusContext('corpus') as c:
q = c.query_graph(c.phone)
q = q.filter(c.phone.speaker.name == 'some_speaker')
q = q.filter(c.phone.discourse.name == 'some_discourse')
results = q.all()
Will result in the following Cypher query:
MATCH (node_phone:phone:corpus)-[:is_a]->(node_phone_type:phone_type:corpus),
(node_phone)-[:spoken_by]->(node_phone_Speaker:Speaker:corpus),
(node_phone)-[:spoken_in]->(node_phone_Discourse:Discourse:corpus)
WHERE node_phone_Speaker.name = "some_speaker"
AND node_phone_Discourse.name = "some_discourse"
RETURN node_phone, node_phone_type
Annotation query optimization
There are several aspects to query optimization that polyglotdb does. The first is that rather than polyglotdb.query.annotations.query.GraphQuery
the default objects returned are actually polyglotdb.query.annotations.query.SplitQuery objects. The behavior of these
objects is to split a query into either Speakers or Discourse and have smaller GraphQuery for each speaker/discourse.
The results object that gets returned then iterates over each of the results objects returned by the GraphQuery
objects.
In general splitting functionality by speakers/discourses (and sometimes both) is the main way that Cypher queries are performant in polyglotdb.
Aspects such as enriching syllables and utterances are quite complicated and can result in out of memory errors if the splits are
too big (despite the recommended optimizations by Neo4j, such as using PERIODIC COMMIT to split the transactions).
Lexicon queries
Note
While the name of this type of query is lexicon, it’s really just queries over types, regardless of their linguistic
type. Phone, syllable, and word types are all queried via this interface. Utterance types are not really used
for anything other than consistency with the other annotations, as the space of possible utterance is basically infinite,
but the space of phones, syllables and words are more constrained, and type properties are more useful.
Lexicon queries are more efficient queries of annotation types than the annotation queries above. Assuming word types have been enriched with a frequency property, a polyglotdb query like:
with CorpusContext('corpus') as c:
q = c.query_lexicon(c.word_lexicon) # Generate LexiconQuery object
q = q.filter(c.word_lexicon.frequency > 100) # Subset of word types based on their frequency
results = q.all()
Would result in a Cypher query like:
MATCH (node_word_type:word_type:corpus)
WHERE node_word_type.frequency > 100
RETURN node_word_type
Speaker/discourse queries
Speaker and discourse queries are relatively straightforward with only a few special annotation node types or attribute types. See Query implementation for an example using a SpeakerQuery.
The special speaker attribute is discourses which will return a list of the discourses that the speaker spoke in,
and conversely, the speakers attribute of DiscourseNode objects will return a list of speakers who spoke in that discourse.
A polyglotdb query like the following:
with CorpusContext('corpus') as c:
q = c.query_speakers() # Generate SpeakerQuery object
q = q.filter(c.speaker.gender == 'male') # Filter to just the speakers that have `gender` set to "male"
q = q.columns(c.speaker.discourses.name.column_name('discourses')) # Return just the speaker name (with the `speaker_name` alias)
results = q.all()
will generate the following Cypher query:
MATCH (node_Speaker:Speaker:corpus)
WHERE node_Speaker.gender = "male"
WITH node_Speaker
MATCH (node_Speaker)-[speaks:speaks_in]->(node_Speaker_Discourse:Discourse:corpus)
WITH node_Speaker, collect(node_Speaker_Discourse) AS node_Speaker_Discourse
RETURN extract(n in node_Speaker_Discourse|n.name) AS discourses
Aggregation functions
In the simplest case, aggregation queries give a way to get an aggregate over the full query. For instance, given the following PolyglotDB query:
from polyglotdb.query.base.func import Average
with CorpusContext('corpus') as c:
q = g.query_graph(g.phone).filter(g.phone.label == 'aa')
result = q.aggregate(Average(g.phone.duration))
Will generate a resulting Cypher query like the following:
MATCH (node_phone:phone:corpus)-[:is_a]->(type_node_phone:phone_type:corpus)
WHERE node_phone.label = "aa"
RETURN avg(node_phone.end - node_phone.begin) AS average_duration
In this case, there will be one result returned: the average duration of all phones in the query. If, however, you wanted
to get the average duration per phone type (i.e., for each of aa, iy, ih, and so on), then aggregation functions
can be combined with group_by clauses:
from polyglotdb.query.base.func import Average
with CorpusContext('corpus') as c:
q = g.query_graph(g.phone).filter(g.phone.label.in_(['aa', 'iy', 'ih']))
results = q.group_by(g.phone.label.column_name('label')).aggregate(Average(g.phone.duration))
MATCH (node_phone:phone:corpus)-[:is_a]->(type_node_phone:phone_type:corpus)
WHERE node_phone.label IN ["aa", "iy", "ih"]
RETURN node_phone.label AS label, avg(node_phone.end - node_phone.begin) AS average_duration
Note
See Aggregate functions for more details on the aggregation functions available.